REST, un style d'architecture universel.
pluralitas non est ponenda sine necessitate
Publié le 15/08/2005 - Mis à jour le 22/09/2006 par Jean-Paul Figer
- Historique de REST
- REST, un style d'architecture, pas un standard
- URI, Ressource et Représentation
- HTTP, GET et POST
- URI logique comme API universelle
- Le travail de l'architecte
- Et la sécurité ?
- Exemples d'utilisation de REST
- REST, services Web, XML, SOA, EAI, SOAP et compagnie...
- Ressource et Objet
Cet article, quoique lisible par tous, est destiné principalement à ceux qui s'intéressent à l'architecture des systèmes informatiques.
Le rasoir d'Ockham (ou d'Occam) est un principe de raisonnement que l'on attribue au moine franciscain et philosophe Guillaume d'Ockham, mais qui était connu et formulé avant lui. Énoncé au XVe siècle, ce principe dit : « Les choses essentielles ne doivent pas être multipliées sans nécessité » (version originale en latin : « pluralitas non est ponenda sine necessitate »). Aussi appelé « principe de simplicité », « principe de parcimonie », ou encore « principe d'économie », il exclut la multiplication des raisons et des démonstrations à l'intérieur d'une construction logique. Le principe du rasoir d'Ockham consiste à ne pas multiplier les hypothèses au-delà du nécessaire, et en d'autres termes à toujours privilégier aussi longtemps que cela reste compatible avec les observations l'hypothèse la plus simple parmi toutes celles qui sont échafaudées. Conan Doyle l'a souvent mis en pratique dans les déductions de Sherlock Holmes.
Extrait de Wikipedia
C'est la même démarche que je propose pour l'architecture des systèmes informatiques : privilégier la solution la plus simple et la plus économe en temps de réalisation et d'exécution. La sélection darwinienne de l'Internet a permis l'émergence de technologies simples, robustes et extensibles de un à un milliard d'utilisateurs. Le Web en général et tous les sites qui ont du succès avec plus de cent millions de visiteurs par mois comme Google, Yahoo, Ebay et Amazon utilisent le style d'architecture REST et le proposent comme méthode privilégiée pour intégrer leurs services Web dans les applications des utilisateurs. Le but de cette introduction à REST est de convaincre les architectes de se servir de ce style d'architecture dans la construction de systèmes informatiques modernes.
Le style d'architecture REST n'est pas limité à la construction de services Web. Il peut être utilisé pour la plupart des systèmes informatiques dont la granularité des échanges est de l'ordre de quelques centaines à quelques dizaines de milliers de caractères.
Historique de REST
REST est l'acronyme de "Representational State Transfer" inventé par Roy T. Fielding dans sa dissertation "an architecture style of networked systems". Il existe une traduction en français ici. Roy T. Fielding participe de puis 1994 aux travaux du W3C sur les sujets URI, HTTP, HTML et WebDAV et a été le co-fondateur du projet Apache, le serveur Web qui équipe 70% des sites Web de tout l'Internet (IIS de Microsoft n'a que 20%). REST décrit les caractéristiques du Web qui en ont fait son succès. L'explication de la signification de REST telle que donnée par Roy T. Fielding est la suivante : "Representational State Transfer évoque l'image du fonctionnement d'une application Web bien construite : un réseau de pages Web (une machine à états finis virtuelle) où l'utilisateur progresse dans l'application en cliquant sur des liens (transition entre états) ce qui provoque l'affichage de la page suivante (représentant le nouvel état de l'application) à l'utilisateur qui peut alors l'exploiter".
REST, un style d'architecture, pas un standard
REST est un style d'architecture, pas un standard. Il n'existe donc pas de spécifications de REST. Il faut comprendre le style REST et ensuite concevoir des applications ou des services Web selon ce style.
Bien que REST ne soit pas un standard, il utilise des standards. En particulier :
- URI comme syntaxe universelle pour adresser les ressources,
- HTTP un protocole sans état (stateless) avec un nombre très limité d'opérations,
- Des liens hypermedia dans des documents (X)HTML et XML pour représenter à la fois le contenu des informations et la transition entre états de l'application,
- Les types MIME comme text/xml, text/html, image/jpeg, application/pdf, video/mpeg pour la représentation des ressources.
REST concerne l'architecture globale d'un système. Il ne définit pas la manière de réaliser dans les détails. En particulier, des services REST peuvent être réalisés en .NET, JAVA, CGI ou COBOL. Vous avez sans doute déjà réalisé des services REST sans le savoir comme Monsieur Jourdain faisait de le prose !
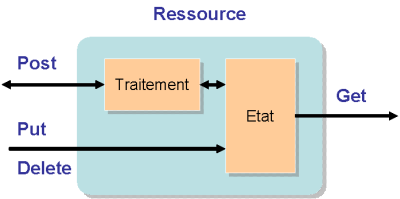
URI, Ressource et Représentation
Le Web est un espace d’information dans lequel les éléments intéressants -Ressources- sont désignés par des identificateurs globaux -URI-. URI est l'abréviation de "Uniform Resource Identifier". Les URI se composent de 2 sous-ensembles URL et URN dont la syntaxe détaillée est décrite ici.
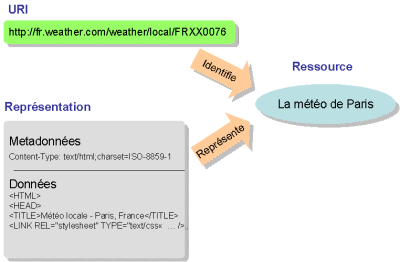
En cliquant sur l'URI suivante http://fr.weather.com/weather/today-Paris-FRXX0076, vous obtenez la météo de Paris. Le fait de cliquer sur le lien indique au navigateur que vous voulez obtenir une représentation de la ressource désignée. Le navigateur reconnaît http comme protocole et envoie alors au serveur fr.weather.com une requête HTTP GET sur le port 80. En retour, le serveur lui envoie la représentation actuelle de la ressource /weather/local/FRXX0076. Cette représentation comporte deux parties, des métadonnées qui décrivent le contenu de la représentation :
Date: Fri, 16 Jan 2009 22:16:10 GMT
Server: Apache
Content-Language: fr-FR
Keep-Alive: timeout=1, max=7482
Connection: Keep-Alive
Content-Type: text/html;charset=UTF-8
Cache-Control: private
Content-Encoding: gzip
Transfer-Encoding: chunked
200 OK
Dans ces métadonnées, on trouve
Content-Type: text/html;charset=UTF-8
ce qui indique que les données qui suivent sont une page HTML codée dans le jeu de caractères UTF-8.
Pour lire facilement ces métadonnées, je vous suggère d'utiliser Firefox ou Chrome et d'installer l'extension Web Developer.
Le Content-Type ou MIME Type est très important puisque c'est lui qui est utilisé par le navigateur pour déterminer le type du fichier, pas l'extension. C'est en fonction de ce type de fichier que le navigateur déterminera l'action à accomplir (visualisation, téléchargement, etc..). Lorsque la même ressource existe sous plusieurs représentations ou plusieurs langages, il est aussi possible à l'agent utilisateur de "négocier" avec le serveur la représentation qui sera fournie. Les types MIME sont attribués par l'IANA.
Les URI ne sont pas limités au schéma HTTP. Voici quelques exemples classiques :
mailto:individu@adresse.org ,
ftp://ftp.futurenet.co.uk/pub/dailyradar/ ,
news:msnews.microsoft.com
sip:jfiger@figer.net
Il est fortement recommandé d'utiliser les schémas et les types MIME qui existent avant de songer à en créer d'autre
Cette notion d'URI est fondamentale car c'est le système global et unique d'identification du Web. L'URI est la pierre angulaire de l'architecture Web. Elle permet d'accéder en un "simple clic" à une multitude de protocoles et de représentations. La portée globale des URI entraîne un effet réseau global. Plus un identifiant est utilisé, plus sa valeur augmente.
Le système d'URI a été largement déployé depuis les débuts du Web et les avantages des URI sont nombreux : liens, favoris, mécanismes de cache, indexation par les moteurs de recherches. En utilisant les URI, il est possible de déployer une application partout dans le monde sans infrastructure additionnelle comme des annuaires ou des "registries". Déployer un autre système de nommage qui aurait les mêmes propriétés que les URI serait très coûteux.
Le premier principe d'architecture consiste donc à identifier les ressources avec des URI.
HTTP, GET et POST
Le deuxième composant de l'architecture REST est le protocole HTTP. Ce protocole comporte deux méthodes principales GET et POST et deux manières de transmettre des paramètres, soit dans l'URI, soit dans les données d'un formulaire.
Quand doit-on employer GET et quand doit-on employer POST ?
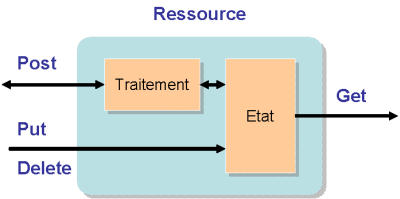
L'utilisation de GET est "sûre" [safe], c'est à dire que l'état de la ressource ne doit pas être modifiée par un GET. Ceci autorise les liens, la mise en cache, les favoris. Il faut donc utiliser GET pour des opérations qui ressemblent à des questions ou à des lectures de l'état de la ressource.
En revanche, il faut utiliser POST quand la demande ressemble à une commande, ou quand l'état de la ressource est modifié ou quand l'utilisateur est tenu pour responsable du résultat de l'interaction.
Deuxième principe de l'architecture REST : le HTTP GET est "sûr", c'est à dire que l'utilisateur ou son agent peut suivre des liens sans obligations.
La conséquence de l'idempotence du GET (deux accès successifs donnent le même résultat) rend l'utilisation du Web plus fiable car un deuxième clic sur un lien ne modifie pas le résultat.
Le protocole HTTP comporte d'autres commandes moins souvent utilisées. HEAD qui est un GET qui ne renvoie que les métadonnées, pas les données. PUT et DELETE pour modifierr ou supprimer une ressource.
Il existe deux documents publiés par le W3C qui donnent tous les détails sur ces principes fondamentaux et dont la lecture est indispensable à tout architecte "Architecture of the World Wide Web" ( traduction en français ici )et "URIs, Addressability, and the use of HTTP GET and POST".
URI logique comme API universelle
L'identification des ressources est la pierre angulaire d'une architecture REST. La définition des URI ne peut donc être la conséquence d'un développement. Les URI doivent être spécifiées au moment de la conception. Les URL manipulées par les serveurs web sont des URL physiques qui reflètent la structure physique des répertoires d'un serveur. Elles comportent des extensions qui dépendent d'un technologie particulière comme .cgi, .aspx ou .php.
Une très bonne solution consiste à représenter les URI de manière indépendante d'une technologie sous la forme d'un hiérarchie. Le plus simple pour comprendre est de consulter un exemple. Pour cela, j'ai crée un groupe, exemple_rest, sous Yahoo Groupes. Son URI est la suivante
http://fr.groups.yahoo.com/group/exemple_rest
En cliquant sur le lien ci-dessus, le navigateur exécute une requête HTTP GET qui permet de d'obtenir une représentation de la ressource. Dans l'en-tête de la réponse, il est indiqué
Content-Type: text/html
On obtient donc l'affichage d'une page html.
Si on clique sur le bouton XML orange à droite dont l'URI est http://rss.groups.yahoo.com/group/exemple_rest/rss on obtient dans l'en-tête de réponse
Content-Type: text/xml
et le navigateur affiche en XML le canal RSS de ce groupe.
En cliquant dans le menu de gauche sur "messages", on obtient la liste des messages avec l'URI http://fr.groups.yahoo.com/group/exemple_rest/messages
et le message n°1 avec l'URI
http://fr.groups.yahoo.com/group/exemple_rest/message/1 .
La logique de construction des URI est évidente. Construire l'application à partir de ces bases devient un jeu d'enfant.
Le site delicious de gestion et de partage de favoris est un autre exemple construit avec des URI logiques qui servent de base directe au système de navigation et de recherche du site.
Les URI indiquées sont des URI logiques indépendantes de toute technologie. Un proxy ou un filtre placé sur le serveur fr.groups.yahoo.com transforme ces URI logiques en URL physiques qui font appel à des pages .aspx, .php ou autre avec des paramètres en fonction de la technologie utilisée. Cette manière de faire présente de nombreux avantages :
- Indépendance par rapport à une technologie particulière,
- Interface (API) universelle entre les composants et les agents utilisateurs,
- Il devient très facile de vérifier les droits d'accès aux ressources au niveau du filtre. Voir le § sur la sécurité.
- La sécurité du site web est renforcée puisqu'on ne peut plus faire d'attaques directes sur les URL des pages Web qui sont masquées.
- Tout navigateur devient un client du pauvre et il est très facile de tester le comportement du système.
- En utilisant https, on peut aisément chiffrer les communications rendant possible l'utilisation en toute sécurité sur l'Internet public et en Wi-Fi.
Voici un autre exemple pour démontrer l'intérêt des URI. Dans ce cas, le serveur renvoie un code barre construit dynamiquement à partir de l'URI sous la forme d'une image. http://www.barcodesinc.com/generator/image.php?code=JEAN-PAUL%20FIGER&style=165&type=C39&width=350&height=100&xres=1&font=3
Le Content-Type est image/jpeg. Je n'ose imaginer l'API compliquée, utilisable uniquement dans un contexte de programmation local, qu'inventerait un programmeur objet pour obtenir dynamiquement un code barre !
Et pour bien enfoncer le clou, imaginons un système Windows où chaque ressource aurait sa propre URI comme
/Démarrer/PanneauDeConfiguration/ConnexionsRéseau/Carte1394/TcpIp/automatique
Le travail de l'architecte
Le premier travail consiste à identifier et à nommer les ressources (au lieu de définir des API !). En aucun cas un URI ne doit être la conséquence d'un développement. Une bonne formation à la définition d'URI consiste à examiner en détail les URI et la navigation de l'exemple de groupe sur Yahoo donné ci-dessus.
- Il faut bien sûr préférer un nommage logique à un nommage physique pour masquer une implémentation spécifique. Sous Apache, il existe un module mod_rewrite qui permet de manière transparente de rediriger une URL vers une autre. Sous IIS, c'est un peu plus compliqué car il n'y a rien en standard. On peut soit écrire un filtre ISAPI, soit utiliser un composant d'une tierce partie.
- Les ressources doivent être identifiées par des noms, pas par des verbes. Les ressources représentent des états, pas des actions. C'est d'ailleurs la grande différence avec des techniques du type RPC ou Objet qui détaillent à l'infini des actions (méthodes).
- Les URI ne doivent pas changer car vous ne saurez jamais qui détient des vieilles références : liens dans d'autres pages, utilisateurs dans leurs favoris, notes sur un bout de papier.
- Le contenu des bases de données ou les entités métiers doivent avoir des URI. Tout navigateur devient un client du pauvre très utile pour les tests. Les références peuvent se trouver dans d’autres médias comme des émails ou de la documentation.. Le XSLT devient utilisable pour présenter, inclure ou transformer les données.
- La toute puissance du HTTP GET et de la représentation hypermédia permet grâce à des liens de construire la navigation ou de fournir progressivement des détails. L'état d'une application est donnée par son URI.
- C'est le client qui tire les représentations des ressources. Chaque requête doit comporter toutes les indications nécessaires pour son exécution et ne doit pas s'appuyer sur un contexte stocké sur le serveur. Tous les services de l'application doivent donc être sans-état (stateless).
Je ne répondrai pas aux messages des architectes qui m'expliqueront que ce n'est pas possible avec force exemples nécessitant une validation à deux phases ("two-phase commit"). Sans-état (Stateless) est un principe d'architecture qui DOIT être respecté pour rester sûr, simple, performant et extensible (scalable). Et c'est toujours possible.
- La représentation des données doit s'appuyer sur des standards comme utf-8 pour le jeu de caractères, le XML pour la syntaxe des documents et des vocabulaires spécifiques (Dublin Core, RSS, Atom...) pour la sémantique des données. C'est le rôle de l'architecte de bien spécifier tous les standards de l'application.
Il faut noter que l'URI logique ne contient pas d'indication sur la manière dont chaque ressource élabore ses réponses. C'est ce qu'on appelle un couplage lâche (loosely coupled). C'est un principe général d'architecture des systèmes informatiques trop souvent oublié qui devient "naturel" avec REST.
Quand la requête est complexe, il faut quelquefois réaliser un formulaire qui construira l'URI à partir de ses données.
Et la sécurité ?
La sécurité (avec la performance) est souvent l'excuse avancée pour faire compliqué alors que seule la simplicité permet d'atteindre cet objectif.
Comme c'est très bien expliqué dans le rapport PITAC de février 2005 remis au Président des Etats-Unis : Cyber Security, a crisis of Prioritization, la faiblesse du modèle habituel de défense périmétrique, généralement utilisé par les entreprises, est devenue douloureusement évidente. Ce modèle, fondé un peu sur le principe de la ligne Maginot, est censé protéger "l'intérieur" d'un système informatique d'un attaquant venu de "l'extérieur". Cependant, dès que la barrière est franchie à la suite d'une vulnérabilité logicielle ou d'une maladresse d'un opérateur, l'attaquant peut compromettre l'ensemble des systèmes sans guère plus d'efforts que pour en compromettre un. Ce n'est pas le seul problème de ce modèle. La distinction entre "intérieur" et "extérieur" s'effondre avec la prolifération d'équipements connectés et la complexité toujours croissante des réseaux interconnectés. Un modèle plus réaliste est le modèle de suspicion mutuelle. Chaque composant d'un système ou d'un réseau est naturellement méfiant envers les autres composants du réseau et demande systématiquement une authentification.
La sécurité des échanges de données doit fournir 4 garanties:
- être sûr de son interlocuteur. C'est l'authentification réciproque des correspondants ou des composants.
- être sûr que les données transmises n'ont pas été modifiées accidentellement ou intentionnellement. C'est l'intégrité des données.
- éviter que les données soient lues par des systèmes ou des personnes non autorisées. C'est la confidentialité.
- éviter la contestation par l'émetteur de l'envoi des données. C'est la signature, appelée aussi non répudiation.
Comment obtenir ces 4 garanties dans une architecture REST ?
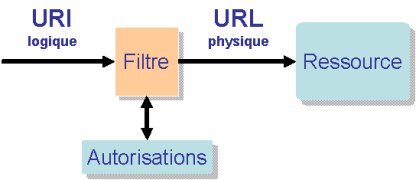
Avec REST et les URI logiques, il devient très facile de mettre en place un système de contrôle d'accès aux ressources. Dans l'exemple ci-dessus de Yahoo groupes, toutes les URI d'accès aux ressources d'un groupe commencent par /group/exemple_rest/ . Il suffit au niveau du filtre de transformation URI logique/URI physique de vérifier que l'utilisateur ou son agent est bien autorisé à accéder au groupe exemple_rest. S'il ne l'est pas, le filtre redirige la requête vers le module d'authentification et, selon la réponse, autorise ou non l'accès. Les avantages de cette méthode sont nombreux :
- indépendance totale entre autorisations et applications (couplage lâche)
- Point d'entrée unique permettant de créer facilement logs et audits.
- Granularité des autorisations possible du niveau le plus global au niveau le plus détaillé, l'ensemble des informations nécessaires étant disponibles dans l'URI logique et la méthode HTTP utilisée.
La version HTTPS du protocole HTTP permet d'authentifier le serveur et de chiffrer les données transmises entre le serveur et un agent utilisateur. L'agent utilisateur peut être authentifié par tous les moyens habituels (nom/mot de passe, certificat, biométrie,...). Ceci permet de traiter de manière sûre le point 1 de la sécurité mentionné plus haut : l'authentification des correspondants. Le point 2 et le point 3 sont obtenus par le chiffrement HTTPS. Le point 4 est obtenu par l'utilisation de certificats par les utilisateurs. Un très haut niveau de sécurité est donc facilement mis en place sur une architecture REST sans complexité supplémentaire.
Exemples d'utilisation de REST
Tous les sites qui ont un grand succès sur l'Internet offrent des interfaces (APIs) pour intégrer les fonctions de ces sites dans des applications ou des serveurs externes. Par exemple, Google offre une impressionnante liste d'APIs pour utiliser ses services en REST. De même Yahoo, avec son "developer network" et une notice sur REST propose de nombreuses méthodes pour exploiter ses services par des programmes. Ebay et Amazon sont plus oecuméniques. Ils offrent non seulement REST mais aussi beaucoup d'autres méthodes. Cependant 85% de leurs utilisateurs choisissent REST. pas en reste permettent d'utiliser leurs moteurs de recherche et d'exploiter les résultats par un programme.
Voici un exemple de recherche avec Yahoo qui renvoie un fichier XML des résultats. J'ai limité le nombre de résultats à 3 sur les plus de 300 000 trouvés.
Voici un autre exemple de création de code barre à la demande qui utilise le service Web décrit plus haut. Il nécessite l'écriture d'une petite ligne de Javascript.
REST, services Web, XML, SOA, EAI, SOAP et compagnie...
Le succès de l'Internet a engendré une pléthore de concepts, de sigles et de promesses dans le domaine de l'architecture des systèmes. Voici quelques définitions pour s'y retrouver.
Services Web
Le terme Services Web a été introduit pour indiquer une interaction entre machines qui ne nécessite pas d'intervention humaine. Les machines parlent aux machines. La plupart des autres concepts ont été inventés pour "standardiser" ce dialogue.
XML
XML fournit une syntaxe unique pour les données sans adhérence avec un logiciel particulier. XML présente comme HTML la particularité de véhiculer les données ET leur description. Ce "gaspillage" s'est révélé très efficace. XSLT et CSS permettent de transformer et de présenter les données XML en fonction de leur usage. Plus de détails...
SOA - Service-oriented Architecture
SOA ou Architecture orientée Services est un style d'architecture destiné à fournir un couplage lâche (loose coupling) entre les composants d'un système. Un service est une fonction métier sans état (stateless) qui accepte des demandes et renvoie des réponses au travers d'un interface bien défini. Les services ne doivent pas dépendre de l'état d'autres fonctions ou services. C'est ce qui permet de les combiner (orchestration) pour obtenir des traitements plus complexes. Il ne suffit pas de découper un système en blocs fonctionnels indépendants pour obtenir une architecture orientée services. Il faut aussi décrire les mécanismes de nommage, d'adressage et d'échange qui permettent ce découplage. Sur le modèle Client Serveur, un exemple de succès est le RSS (plus de détails...) qui permet un découplage parfait entre le producteur et le consommateur de données alors que CORBA/DCOM sont des échecs sérieux.
EAI - Enterprise Application Integration
L'EAI est un ensemble d'outils et de méthodes destiné à consolider, moderniser et coordonner les applications existantes dans une entreprise. Trop souvent, ces outils ne font qu'ajouter une couche supplémentaire de logiciels sans diminuer la complexité des systèmes. Le meilleur EAI que je connaisse est tout simplement XML+HTTP.
SOAP
SOAP est un style d'architecture qui permet d'échanger des messages XML entre applications selon le modèle RPC (Remote Procedure Call). SOAP ne respecte ni le style REST ni même le style SOA puisque c'est un moyen de véhiculer des interfaces RPC spécifiques d'une application dans un tuyau standard. Il est donc à terme condamné à s'aligner ou à disparaître. Voir ici pourquoi SOAP est quand même un standard W3C : édifiant! Si l'interopérabilité avec SOAP est indispensable, il est facile d'ajouter des connecteurs SOAP sur une architecture REST. Il est à noter que de nombreux vendeurs "poussent" SOAP car très proche des anciens concepts et essaient de lui trouver une "raison d'être" face à REST. La démonstration est très loin d'être convaincante.
Ressource et Objet
Au début des années 1990, la technologie objet était considérée comme la technologie la plus prometteuse pour écrire du logiciel. Force est de constater que quinze ans plus tard, cette technologie n'a pas apporté ce que l'on en attendait. Ce qui fonctionnait très bien avec des petits programmes n'a pas supporté le "passage à l'échelle". La communication inter programmes avec des objets distribués comme RMI, CORBA ou DCOM a été un échec sérieux. Imaginons ce que deviendrait l'exemple donné plus haut de fourniture de code barres en programmation objet.
Bien que les ressources ressemblent à des objet, en particulier pour les propriétés,il y a beaucoup de différences. La plus grosse différence est liée au nombre de méthodes. La programmation objet a tendance à multiplier les méthodes ce qui augmente la complexité des interfaces alors que REST a seulement 2 méthodes principales, GET et POST. En revanche, le style REST a tendance à multiplier les URI des ressources. Cependant, c'est L'URI associé à HTTP GET permet de réduire l'adhérence entre les composants à un minimum.
Ajoutez vos commentaires ci-après ou les envoyer à Jean-Paul Figer

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International.