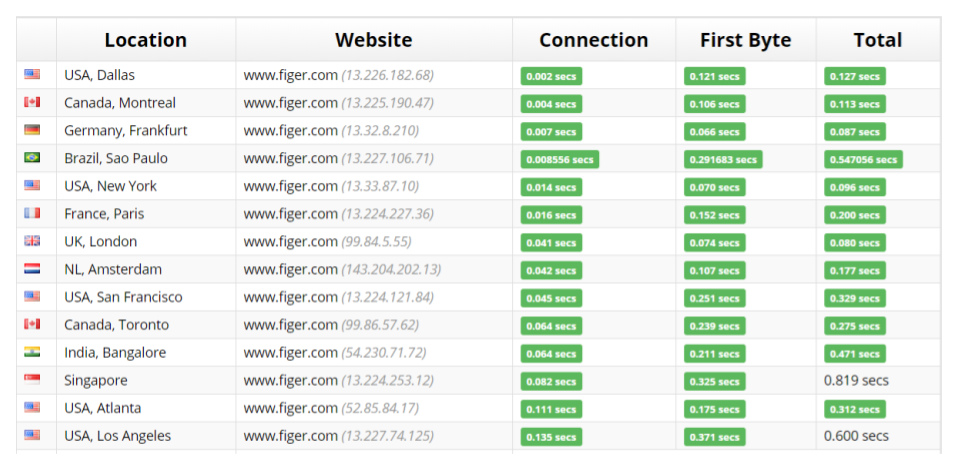
Serverless sur le Cloud
Comment réaliser un site très performant sans serveur
Publié le 19/02/2020 - Mis à jour le 19/03/2020 par Jean-Paul Figer
- Historique du site depuis 1970
- Principe de fonctionnement de l'ancien système
- Principe de fonctionnement de Jekyll
- Une mise à jour en WYSIWYG des documents
- Le stockage des images et des autres documents
- Déploiement du site
- Architecture Serverless AWS avec Cloudfront sur S3
- Ajouter des fonctions dynamiques à des pages statiques ?
Historique du site depuis 1970
Je recevais souvent des demandes de conseil sur des choix d'équipements ou sur tel ou tel sujet technique. Au début des années 70, j'avais préparé des fiches papier que je photocopiais pour répondre à ces demandes. L'arrivée de l'émail au milieu des années 80 m'a simplifié la vie. Avec Compuserve d'abord en 1987 puis le Web en 1995, c'est devenu self service. Cependant, le nombre de sujets a considérablement augmenté. Ce site s'est donc progressivement étoffé. La mise à jour est devenue de plus en plus complexe et longue.
En 1998, j'ai décidé d'automatiser au maximum les tâches. La plupart des logiciels disponibles pour la mise à jour d'un site étaient compliqués. Il fallait presque tout faire à la main. Ces outils généraient un code HTML infâme (en particulier FrontPage). J'ai donc développé mon système de "Gestion de contenu" à partir des standards de l'Internet. Ce site me servait ainsi de banc d'essai des technologies du web. L'accroissement de la fréquentation m'a amené à privilégier les solutions performantes. J'ai progressivement introduit les standards XML 1.0, XHTML 1.0, CSS 2.0, XSLT 1.0 XPATH 2.0 en essayant de perturber le moins possible le fonctionnement du site. C'est un peu comme changer le moteur d'un avion en plein vol. Depuis 2003, je peux modifier la présentation du site en un seul clic. En 2005, j'ai ajouté la mise à jour directe des pages dans le navigateur.
Au début le serveur tournait sur un PC à la maison, puis sur une machine louée chez un hébergeur en ligne pour finalement adopter en 2008 un serveur Cloud sur AWS. Fiabilité et performances excellentes, coût réduit à 15$ par mois. Le seul problème restait la mise à jour incessante des logiciels du serveur (Ubuntu Linux, Apache2, PHP, ...) et des certificats https.
Progressivement, l'offre de services d'AWS sur le Cloud s'est étoffée au delà du calcul (EC2) et du stockage (S3) avec Cloudfront, Route53, Certificate server, Lambda, API gateway. Ces technologies permettent sans serveur d'héberger des pages sur S3 et de les distribuer dans le monde entier via le système Cloudfront. Avec route53 pour gérer le DNS du domaine figer.com et Certificate server pour gérer automatiquement le renouvellement des certificats https, la maintenance du serveur était réduite à zéro. Il restait le point épineux de la maintenance des pages du site. Je n'étais pas le seul à avoir ce problème. Le fondateur de Github, Tom Preston-Werner, a développé un générateur de site statique Jekyll pour simplifier l'effort de création et de maintenance de la documentation des dizaines de millions de programmeurs sur Github. L'idée était la même que celle que j'avais développée en 1998 : générer automatiquement des pages statiques web pour des sites statiques comme la documentation juste à partir du contenu. Avec l'aide des services AWS, on sert ces pages statiques web depuis S3 sans serveur. Résultat, plus de maintenance de serveur, des performances excellentes (pas de traitement à l'exécution) et des coûts très réduits (2$ par mois au lieu de 15$ !). Le but de cet article est d'expliquer comment réaliser et gérer un site sans serveur.
Principe de fonctionnement de l'ancien système
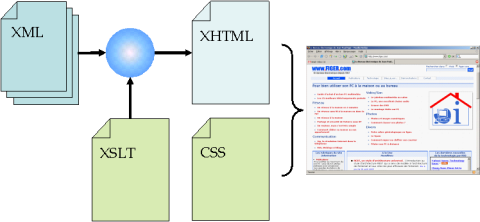
Chaque page du site est un document XML qui rassemble le contenu de la page et des métadonnées nécessaires à la publication des articles (dates d'écriture et de mise à jour, URL de référence, document publié ou non, ...). Pour éviter d'inventer un nouveau langage XML, ce document XML est écrit en XHTML.
La chaîne de production à partir de ce document XHTML est la suivante :
- Transformation XSLT pour générer le document en XHTML
Les en-têtes et les pieds de page, le sommaire, la navigation, les métadonnées, les indications de style et la publicité Google sont ajoutés.
Je n'ai donc qu'un seul document XSLT à modifier pour changer la structure et la présentation de toutes les pages du site. - Application d'une feuille de style CSS pour la mise en page finale.
Cette feuille est téléchargée par le navigateur de l'utilisateur qui applique le style localement. Ce système réduit la taille de chaque page et augmente les performances puisque la feuille de style, unique pour l'ensemble du site, est donc téléchargée une seule fois. Cette technique permet aussi d'utiliser des feuilles de style différentes selon la destination des pages, par exemple, pour éditer une version des pages adaptée à l'impression.
Après chaque modification, on sauvegarde la page modifiée dans le répertoire des pages en conservant la version précédente. Pour que la modification soit visible dans le site, il faut "publier" la page en cliquant sur le lien correspondant. On peut "voir" la page sans la publier.
Principe de fonctionnement de Jekyll
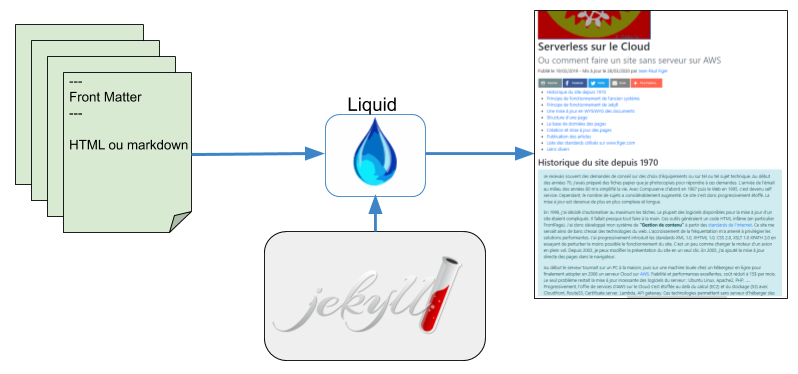
C'est exactement le même principe que celui de mon ancien système ! On stocke dans chaque page les métadonnées nécessaires. A chaque mise à jour d'un document, Jekyll régénère l'ensemble des pages du site dans un répertoire temporaire d'un service web local (http://localhost:4000) que l'on peut visualiser dans un navigateur. Le contenu des pages est écrit soit en html soit en Markdown (extension .md) converti en html à chaque mise à jour du contenu. Le Markdown est un système simple pour ajouter des indications de présentation HTML à des documents texte sans avoir à connaître le HTML. Quitte à apprendre un nouveau langage, autant apprendre les quelques balises HTML nécessaires à la présentation du texte.
Tous les fichiers qui contiennent en tête un "Front Matter" c'est à dire des lignes de texte (en yaml) encadrées par trois traits d'union sont traitées par Jekyll. C'est l'équivalent de mes métadonnées en XML. Les autres fichiers statiques sont recopiés sans modification.
--- layout: page title: Serverless sur le Cloud ---La génération des pages HTML de mon ancien système par une transformation XSLT est remplacée par le moteur de template Liquid utilisé par Jekyll pour exploiter les métadonnées "Front Matter" des pages. C'est moins puissant que XSLT mais c'est beaucoup plus simple.
<h1> {{ page.title }} </h1>
Il est possible d'ajouter ses propres métadonnées (sous la forme clé: valeur) en plus de celles intégrées par défaut dans Jekyll. Les opérations ne sont pas limitées à une page mais peuvent être globales à l'ensemble des pages du site pour générer et trier des listes de pages par exemple.Il y a bien sûr quantité de plug-ins Jekyll pour des opérations particulières comme générer automatiquement une table des matières pour chaque document, etc...
On peut aussi inclure des fichiers pré-traités par Liquid. De cette manière, les en-têtes et les pieds de page, les index, la navigation, les métadonnées du site, les indications de style et la publicité Google sont ajoutés automatiquement à chaque page par Jekyll. La régénération complète de mon site d'une centaine de pages dure 26 secondes.
Pour plus détails voir cet excellent guide.
J'en ai aussi profité pour ne plus développer de feuille de style CSS3 en utilisant telle quelle l'excellente librairie Bootstrap 4. Elle rend un site "responsive", "mobile-first" sans effort, juste en insérant des indications de "class" sur les éléments HTML5. En 2020, environ la moitié de mes visiteurs utilise des mobiles.
Une mise à jour en WYSIWYG des documents
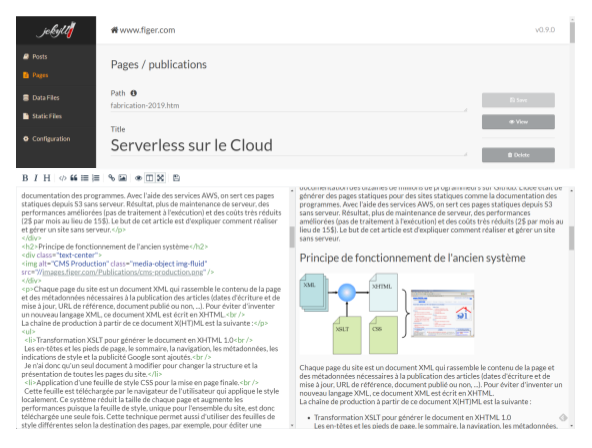
Les pages sont de simples fichiers texte écrits avec un "front matter" en yaml puis un contenu en html ou en markdown. La mise à jour peut se faire avec n'importe quel éditeur de texte plus ou moins évolué. Pour une approche plus WYSIWYG, il y a plusieurs solutions, la plus simple étant d'utiliser le plugin Jekyll-admin. Celui-ci fournit une interface web (http://localhost:4000/admin) pour visualiser et modifier en direct les fichiers texte du site.
Le stockage des images et des autres documents
Il serait possible d'insérer les images et autres documents dans le répertoire du site. Jekyll les recopierait dans le site à chaque déploiement. Or, ces documents sont souvent à la fois nombreux et volumineux. Il est aussi intéressant d'avoir une adresse web (URI) fixe pour chaque document de manière à pouvoir les utiliser dans plusieurs projets. Le stockage S3 d'AWS fournit en natif une solution très simple pour rendre ces fichiers accessibles sur le web. C'est donc la solution que j'ai choisi d'autant que la durabilité garantie du service est de 99,999999999 %. Depuis 2006, date d'ouverture du service, je n'ai pas perdu un seul fichier. Ces documents sont facilement téléchargés sur S3 à l'aide du logiciel gratuit S3 Browser.
Déploiement du site
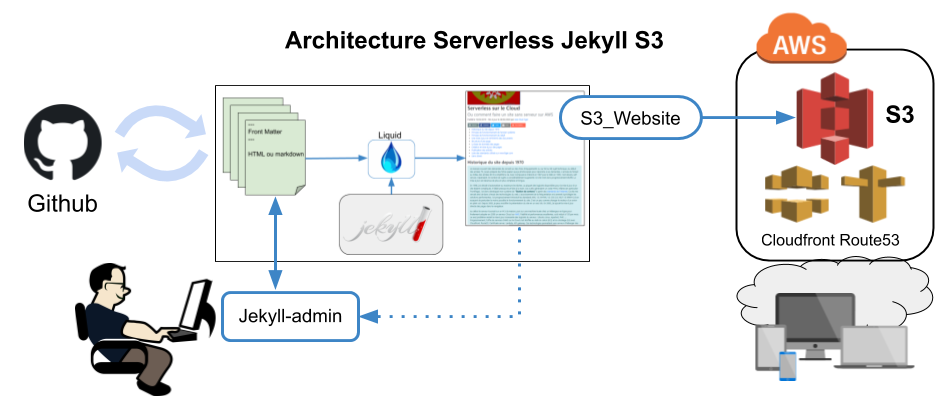
Jekyll permet de créer, modifier et tester facilement un site statique en local sur n'importe quelle machine. Il reste deux tâches importantes à accomplir : la gestion du code et le déploiement du site.
- Pour gérer et sauvegarder le code, j'utilise naturellement Github. Depuis le rachat par Microsoft, Github est devenu complètement gratuit pour un usage personnel avec un nombre illimité de répertoires publics ou privés. Github via Git permet d'historiser toutes les modifications et de réinstaller le projet en un clic sur n'importe quelle machine
- Pour déployer le site, il existe beaucoup de solutions manuelles ou automatiques qui sont indiquées ici. Ayant choisi S3 comme solution moderne et économique pour héberger les pages, j'utilise le plugin Jekyll s3_website dont le fonctionnement est très simple puisqu'il suffit, après configuration initiale, de lancer la commande
s3_website push. Le déploiement dure quelques secondes.
Architecture Serverless AWS avec Cloudfront sur S3
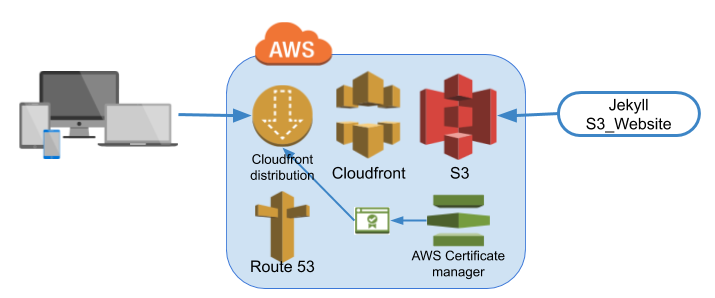
A ce stade, le site statique est généré par Jekyll dans le répertoire local _site.
Les technologies utilisées sont les suivantes :
- AWS S3 : le plugin Jekyll s3_website invalide le cache Cloudfront et recopie le site dans le répertoire (bucket) S3
-
AWS Cloudfront : distribue les fichiers du répertoire S3 dans ses points de présence répartis dans le monde entier. Il sert le site
https://www.figer.com. Il redirige les requêteshttp://figer.com,http://www.figer.comethttps://figer.com. Il est accessible aussi en IPv6 et implémente le nouveau protocole HTTP/2 plus performant. - AWS Route 53 : c'est le DNS (Domain Name System) couplé à Cloudfront. Quand un utilisateur tape www.figer.com dans son navigateur, Route 53 fournit une adresse IP d'un point de présence Cloudfront proche de l'utilisateur.
- AWS Certificate manager : génère et distribue à Cloudfront le certificat (TLS/SSL) indispensable pour sécuriser le protocole https. Ce certificat est généré et surtout renouvelé automatiquement, le tout gratuitement.
Ajouter des fonctions dynamiques à des pages statiques ?
C'est bien sûr possible ! La solution générique consiste à appeler des fonctions dynamiques gérées sur le Cloud par un formulaire ou du Javascript. Il y a quantité d'offres sur l'Internet pour répondre à des besoins génériques : par exemple, sur ce site, j'utilise Disqus pour gérer les commentaires sur les articles, Logz.io pour analyser les logs du site, Google Search Console pour la recherche dans le site figer.com, feedburner pour gérer les abonnements aux flux RSS, Google analytics pour la fréquentation du site. j'ai remplacé Formspree pour envoyer des mails par Simple Email Service (SES) d'Amazon au travers d'une fonction Lambda Serverless. Il est même possible d'ajouter les fonctions eCommerce !
Ajoutez vos commentaires ci-après ou les envoyer à Jean-Paul Figer

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International.