De l'ASCII à l'UTF-8
Tout comprendre sur les jeux de caractères
Publié le 13/02/2006 - Mis à jour le 20/06/2012 par Jean-Paul Figer
Tout le monde sait que la plus petite unité d'information est le bit qui peut prendre la valeur 0 ou 1. Les ordinateurs manipulent généralement les bits par groupe de 8, appelé octet. Un octet peut prendre 256 valeurs comprises entre 0 et 255. Pour représenter une valeur plus grande, il faut utiliser plusieurs octets.
Pour représenter des caractères dans un fichier texte, on associe un nombre (code) à une lettre, à un chiffre ou à un symbole. Par exemple, 65 pour A, 66 pour B, etc... Un des premiers standards crée en 1967 a été le code ASCII (American Standard Code for Information Interchange). Le code ASCII est un code à 7 bits qui définit les codes de 0 à 127 pour les caractères anglais, les nombres de 0 à 9 et certains caractères spéciaux comme indiqué ci-après.
!"#$%&'()*+,-./0123456789:;<=>?
@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
`abcdefghijklmnopqrstuvwxyz{|}~
Il ne définit pas les codes de 128 à 255 et ne comporte pas les lettres accentuées qui sont nécessaires pour la plupart des langages européens.
Comme l'ASCII était très limité, l'ISO (International Organization for Standardization) a crée des standards pour les codes de 128 à 255. Le plus utilisé est le standard ISO-8859-1, connu aussi sous le nom Latin 1, qui inclut les lettres accentuées nécessaires pour la plupart des langages européens comme le français, l'allemand, l'espagnol, le norvégien. Cependant, il y a beaucoup d'autres langages qui ont besoin de codes spéciaux non inclus dans l'ISO-8859-1. L'euro € , création récente, n'existe pas non plus dans l'ISO-8859-1. L'ISO a donc crée une gamme de codes de ISO-8859-1 à ISO-8859-10. L'esperanto est codé en ISO-8859-3 ou Latin 3. Tous ces codes sont des codes à un octet qui sont identiques au code ASCII pour les caractères de 0 à 127 et qui comportent les caractères accentués ou spéciaux dans les codes 128 à 255.
Chaque constructeur d'ordinateur a aussi développé ses propres codes non conformes aux standards internationaux (IBM EBCDIC, Windows-1252,..)
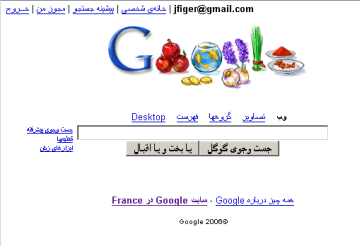
Cette situation était acceptable quand on utilisait un document écrit dans une seule langue. L'arrivée de l'Internet a tout bouleversé. La nouvelle demande était de représenter simultanément tous les caractères de toutes les langues comme dans cet exemple.
Unicode
Quelques langages ont un très grand nombre de caractères comme le chinois, le japonais ou le coréen. Il a donc fallu utiliser au moins deux octets au lieu d'un pour les représenter. Avec deux octets, on dispose de 256*256 = 65536 codes.
Xerox et Apple unirent leurs efforts en 1986/1987, pour développer un jeu de caractères unique, en particulier pour traiter correctement le problème du chinois et du japonais. Il a fallu attendre juin 1992 pour voir enfin émerger les spécifications de l'Unicode V1.0. En 2006, c'est la version 4 qui est en usage. Le consortium Unicode a pour devise "un seul nombre pour chaque caractère, quelque soit la plate-forme, le programme ou le langage".
La mise au point et l'adoption de l'Unicode a été très lente car le codage des caractères posait de gros problèmes techniques et politiques. La représentation sous 2 octets de l'Unicode dite UTF-16 doublait la taille des documents, d'une manière considérée comme inutile pour la majorité des systèmes installés. Un autre problème était plus sournois : les différents constructeurs ne rangeaient pas les octets dans la mémoire dans le même ordre. On peut ranger les huit bits de poids forts en premier ou en deuxième dans la mémoire. Ce n'est pas très important puisque dans la même machine ou dans le même programme, on les relira dans le bon ordre. C'est plus ennuyeux pour échanger des données. On a donc défini deux standards dits UTF-16 Little Endian et UTF-16 Big Endian. Par exemple Microsoft Word utilise UTF-16 Little Endian et c'est UTF-16 Big Endian qui est recommandé pour l'Internet. La plupart des fichiers UTF-16 commencent par deux caractères qui indiquent l'ordre dans lequel les caractères sont stockés. Les autres problèmes étaient de nature politique : c'est quoi un caractère ? Le ss en allemand est-il un caractère ou un double s et il a fallu beaucoup de temps pour s'accorder sur une définition commune des caractères pour toutes les langues.
Et naquit l'UTF-8
Pour résoudre le problème du doublement de la taille des fichiers et de l'incohérence des représentations, Ken Thompson, un des pères d'UNIX, a littéralement inventé le 2 septembre 1992 sur un coin de table le codage UTF-8, une autre manière de coder les caractères Unicode. L'idée a été de coder les caractères les plus utilisés de 0 à 127 sur un octet, de coder les caractères de 128 à 1023 sur 2 octets et au-dessus de 1023 sur 3 octets et ce jusqu'à 4 octets. Le but de cet article n'est pas de décrire dans les détails le codage UTF-8 mais d'en expliquer les principes car il est devenu le standard de l'Internet, donc de l'informatique. Par exemple, l'UTF-8 est devenu le codage par défaut des documents en XML donc en XHTML.
Le système de codage est simple. Le bit de poids fort d'un caractère sur un octet est toujours 0. Les bits de poids forts d'une séquence de caractères représentée sur plusieurs octets sont 110 pour 2 octets, 1110 pour 3 octets et 11110 pour 4 octets. Les caractères suivants dans une séquence ont 10 en poids forts. Ces caractéristiques sont intéressantes à plusieurs titres.
- Un texte écrit en US-ASCII reste inchangé. Le passage à l'UTF-8 est invisible pour les américains. En revanche un texte écrit en ISO-8859-1 est modifié pour les lettres accentuées représentées en UTF-8 sur 2 caractères. La taille d'un texte avec des accents est donc seulement augmentée de quelques pour cents.
- Le jeu de caractères est "sans-état" [stateless], la signification d'un caractère ne dépendant pas d'un marqueur dans une séquence. Un caractère manquant dans la séquence détruit la représentation du caractère mais pas plus, car on peut se re-synchroniser au caractère suivant. C'est donc un code très robuste.
- La représentation d'un caractère ne peut pas être contenue dans la représentation d'une chaîne plus grande, ce qui permet de faire des recherches de sous-chaînes par comparaison d'octets, comme sur les codages à un octet.
Ces caractéristiques en font donc le codage à préférer pour toutes les applications. Il a fallu beaucoup de temps pour que ce codage, nettement supérieur aux autres, s'impose. Par exemple, utf-8 est devenu le codage natif à partir de la plate-forme .NET et de la version SQL Server 2005 chez Microsoft. En 2012, plus de 60% des caractères sur le web sont en utf-8 et même 80% si on inclut le sous-ensemble l'ASCII. Voir ici
Comment désigner un document codé en UTF-8 sur le Web ?
La migration vers UTF-8 sera progressive. En attendant, il faut vivre avec de multiples codages pour les jeux de caractères, donc spécifier le codage utilisé dans chaque document.
Le protocole HTTP permet très facilement d'indiquer le type de codage dans le header. Il suffit d'indiquer
Content-Type: text/html; charset=utf-8
pour un document HTML ou
Content-Type: text/plain; charset=utf-8
pour un document de type texte.
Si vous ne pouvez pas modifier le header de votre serveur HTTP, il suffit d'insérer dans la section head
<meta content="text/html; charset=utf-8" http-equiv="Content-Type" />
Cette méthode ne fonctionne évidemment que pour les documents HTML.
Pour un document XML, le type de codage est indiqué sur la première ligne du document comme suit
<?xml version="1.0" encoding="UTF-8"?>
A noter qu'on peut utiliser indifféremment UTF-8 ou utf-8
Liens utiles
Ajoutez vos commentaires ci-après ou les envoyer à Jean-Paul Figer

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International.