
Comment est construit ce site ?
Les coulisses de www.figer.com
Publié le 27/12/2005 - Mis à jour le 28/12/2008 par Jean-Paul Figer
Archive
Cet article n'est plus mis à jour et est conservé comme archive
- Bref historique du site
- Principe de fonctionnement
- Une mise à jour en WYSIWYG des articles !
- Structure d'une page
- La base de données des pages
- Création et mise à jour des pages
- Publication des articles
- Liste des standards utilisés sur www.figer.com
- Liens divers
Bref historique du site
Je recevais souvent des demandes de conseil sur des choix d'équipements ou sur tel ou tel sujet technique. Au début des années 70, j'avais préparé des fiches papier que je photocopiais pour répondre à ces demandes. L'arrivée de l'émail au milieu des années 80 m'a simplifié la vie. Avec Compuserve d'abord en 1987 puis le Web en 1995, c'est devenu self service. Cependant, le nombre de sujets a considérablement augmenté. Ce site s'est donc progressivement étoffé. La mise à jour est devenue de plus en plus complexe et longue.
En 1998, j'ai décidé d'automatiser au maximum les tâches. La plupart des logiciels disponibles pour la mise à jour d'un site étaient compliqués et il fallait presque tout faire à la main. Ces outils généraient un code HTML infâme, en particulier FrontPage. J'ai donc développé mon système de "Gestion de contenu" à partir des standards de l'Internet. Ce site me servait ainsi de banc d'essai des technologies du web. L'accroissement de la fréquentation m'a amené à privilégier les solutions performantes. J'ai progressivement introduit les standards XML 1.0, XHTML 1.0, CCS 2.0, XSLT 1.0 XPATH 2.0 en essayant de perturber le moins possible le fonctionnement du site. C'est un peu comme changer le moteur d'un avion en plein vol. Depuis 2003, je peux modifier la présentation du site en un seul clic. En 2005, j'ai ajouté la mise à jour directe des pages dans le navigateur. C'est ce que je vais décrire maintenant.
Principe de fonctionnement
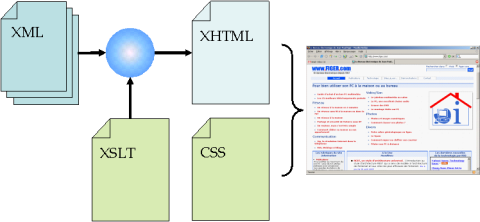
Chaque page du site est un document XML qui rassemble le contenu de la page et des métadonnées nécessaires à la publication des articles (dates d'écriture et de mise à jour, URL de référence, document publié ou non, ...). Pour éviter d'inventer un nouveau langage XML, ce document XML est écrit en XHTML !
La chaîne de production à partir de ce document X(HT)ML est la suivante :
- Transformation XSLT pour générer le document en XHTML 1.0
Les en-têtes et les pieds de page, le sommaire, la navigation, les métadonnées, les indications de style et la publicité Google sont ajoutés.
Je n'ai donc qu'un seul document à modifier pour changer la structure et la présentation de toutes les pages du site. - Application d'une feuille de style CSS pour la mise en page finale.
Cette feuille est téléchargée par le navigateur de l'utilisateur qui applique le style localement. Ce système réduit la taille de chaque page et augmente les performances puisque la feuille de style, unique pour l'ensemble du site, est donc téléchargée une seule fois. Cette technique permet aussi d'utiliser des feuilles de style différentes selon la destination des pages, par exemple, pour éditer une version des pages adaptée à l'impression.
Après chaque modification, on sauvegarde la page modifiée dans la base de données des pages en conservant la version précédente. Pour que la modification soit visible dans le site, il faut "publier" la page en cliquant sur le lien correspondant. On peut "voir" la page sans la publier.
Une mise à jour en WYSIWYG des articles !
WYSIWYG (What you see is what you get) est l'acronyme d'un système de mise à jour qui permet à l'utilisateur de voir immédiatement le résultat final sans étape intermédiaire.
Le point faible du système restait la mise à jour du contenu des articles. Chaque article est écrit en X(HT)ML. A chaque mise à jour du texte XML d'un article, il fallait cliquer sur un bouton pour voir le résultat final. Ce n'était pas très pratique. Il existe bien des outils d'édition de page Web en WYSIWYG mais ces outils modifient le texte XHTML résultat, pas le XML source. Comment reporter la mise à jour de la page Web sur le texte XML source ? J'ai enfin trouvé une solution très spectaculaire qui permet d'éditer directement le XML source dans le navigateur après application du style !
Cette solution est fondée sur deux technologies complémentaires.
- La première technologie, c'est l'existence d'un outil qui permet d'éditer une page XHTML dans le navigateur. J'ai d'abord utilisé un outil tout à fait remarquable, Mozile . Cependant, ce système ne fonctionnait que dans le navigateur Firefox. En 2008, la version de Firefox 3.0 l'a rendu incompatible. J'ai donc cherché une autre solution et j'ai trouvé un outil beaucoup plus complet, adopté par la plupart des systèmes de gestion de contenus TinyMCE qui est vraiment le couteau suisse de l'édition HTML en ligne. Son seul défaut, une documentation squelettique complétée par quelques exemples qui demande beaucoup d'essais pour trouver les bons paramètres.
- La deuxième technologie consiste à ne pas inventer de nouvelles balises XML comme c'est le premier réflexe. En effet, ces balises ne seraient pas traités par le système d'édition XHTML Il suffit au contraire de réutiliser les balises XHTML. Pour personnaliser, on réutilise les attributs qui existent comme "id" ou "class" ou "title". J'ai découvert un an après que je n'étais pas le seul à avoir eu cette idée. Elle est maintenant déclinée pour de nombreux formats de documents sous le nom de microformats. Cette "astuce" permet de rendre les documents XML compatibles XHTML donc visibles dans un navigateur sans transformation. Ce faisant, on réutilise une base de balises bien mieux conçue que celle qui serait développée seul sur le coin d'une table.
En combinant ces deux technologies, on peut donc éditer directement le XML au format XHTML dans le navigateur. J'ai profité de cette occasion pour "nettoyer" mon système de gestion de contenu. C'est le nouveau système que je vais décrire maintenant.
Structure d'une page
Chaque page est un élément XML qui, comme tout document HTML comporte deux enfants et . L'élément comporte les métadonnées de la page en Dublin Core préfixées "DC." et des paramètres utilisés par mon système. L'élément comporte le texte de l'article en XML avec des balises XHTML pour la présentation du texte. Cette "astuce" permet de lire le document XML en format XHTML dans tout navigateur standard comme indiqué plus haut. Le jeu de caractères utilisé est de l'unicode représenté en utf-8 qui permet de traiter simultanément tous les jeux de caractères du monde sans augmenter la taille des données. Pour voir le document XML, il suffit de cliquer sur le logo XML en tête de chaque article. L'élément d'un article comporte deux éléments
La base de données des pages
L'ensemble des pages (éléments XML) est regroupé dans un élément ... stocké sous la forme d'un simple fichier texte en XML : base-articles.xml. Cette base de données minimaliste représente un fichier de 1.2 Mo pour l'ensemble des articles du site, moins qu'une base de données conventionnelle vide ! Le fichier base-articles.xml est sauvegardé à chaque modification dans un fichier archive compressé. La compression zip divise à peu près par 4 la taille du fichier de sauvegarde. Le paramètre DC.source indique l'URI relative de chaque page du site. On peut donc stocker dans la base plusieurs versions d'un même article.
Création et mise à jour des pages
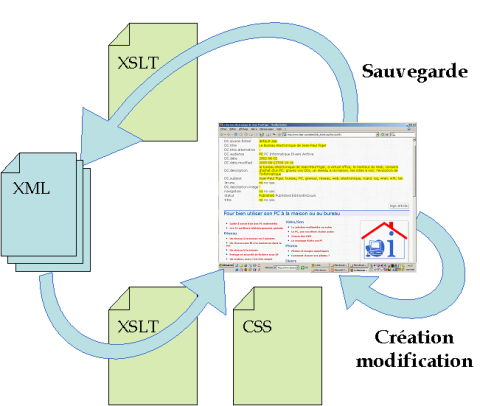
Chaque page peut servir de modèle pour une nouvelle page. Elle est simplement recopiée dans la base avec un nouvel identifiant. C'est donc la même fonction mise à jour qui est utilisée pour la création ou la modification des pages. C'est là qu'intervient le système qui permet dans un navigateur d'éditer directement le texte XHTML vu après application de la feuille de style CSS. La mise à jour se fait dans le navigateur sur la mise en page finale aussi simplement que dans un traitement de texte. Lors de la sauvegarde de l'article, on stocke tout simplment la nouvelle version dans la base Articles. La version précédente de l'article est marquée comme une version archive avec la date et l'heure de sauvegarde.
Les autres fichiers du site, comme les images, sont stockées directement dans des dossiers en utilisant Webdav (dossiers Web dans le jargon Microsoft). Les dossiers et fichiers apparaissent donc comme des fichiers locaux dans les favoris réseaux. Il n'est donc pas besoin d'un outil spécifique pour la mise à jour de ces fichiers dans le site.
Publication des articles
Une métadonnée "statut" permet de marquer chaque article comme "En cours d'édition" ou "publié". On peut publier chaque article séparément. Cependant, un certain nombre de pages ou de fichiers font la synthèse du contenu du site comme La une ou les canaux ATOM ou RSS. Il existe donc une fonction "Tout publier" qui permet d'être sûr de mettre à jour simultanément toutes les pages en recréant les fichiers globaux.
Liste des standards utilisés sur www.figer.com
Chaque standard renvoie vers un lien sur la spécification du standard et l'identification du standard est indiquée
Liens divers
L'image de l'engrenage qui illustre cet article provient du site de Serge Cabala.
Ajoutez vos commentaires ci-après ou les envoyer à Jean-Paul Figer

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International.